

Conquering Data Challenges For Your Generative AI Success
Embarking on the journey of implementing successful Generative AI requires a strong and reliable foundation, with data preparation at its heart.
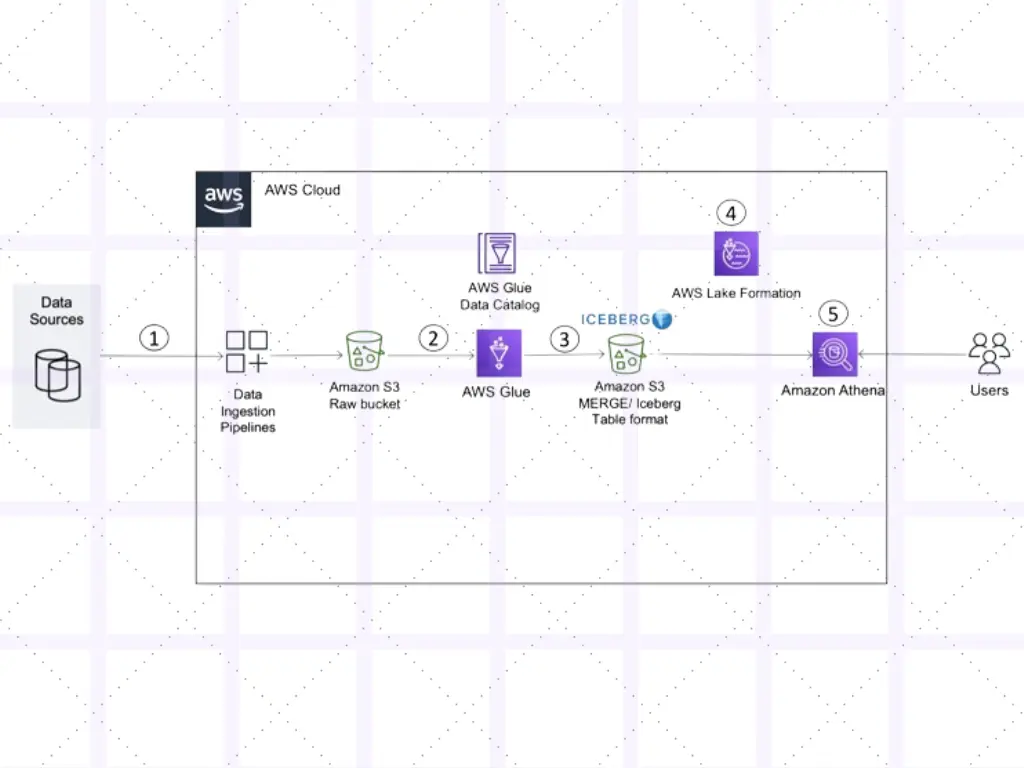
Embarking on the journey of implementing successful Generative AI requires a strong and reliable foundation, with data preparation at its heart.

No AI strategy can thrive or endure without high-quality data because data is the lifeblood that fuels generative AI…
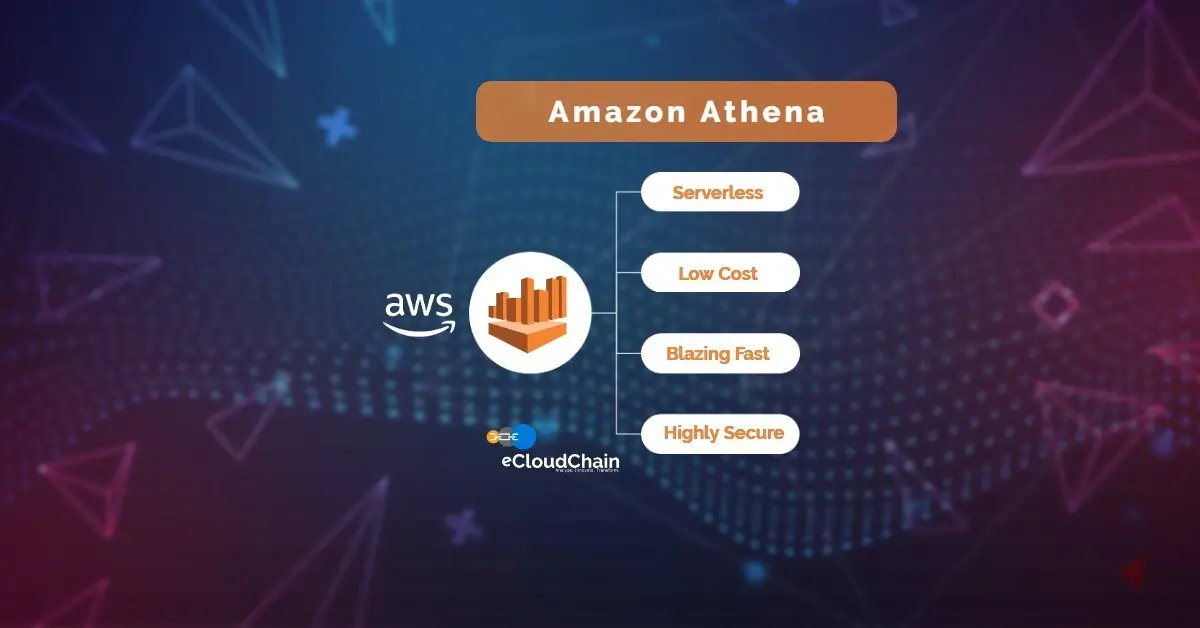
Amazon Athena lets you query data where it lives without moving, loading, or migrating it. You can query the data from relational, non-relational…
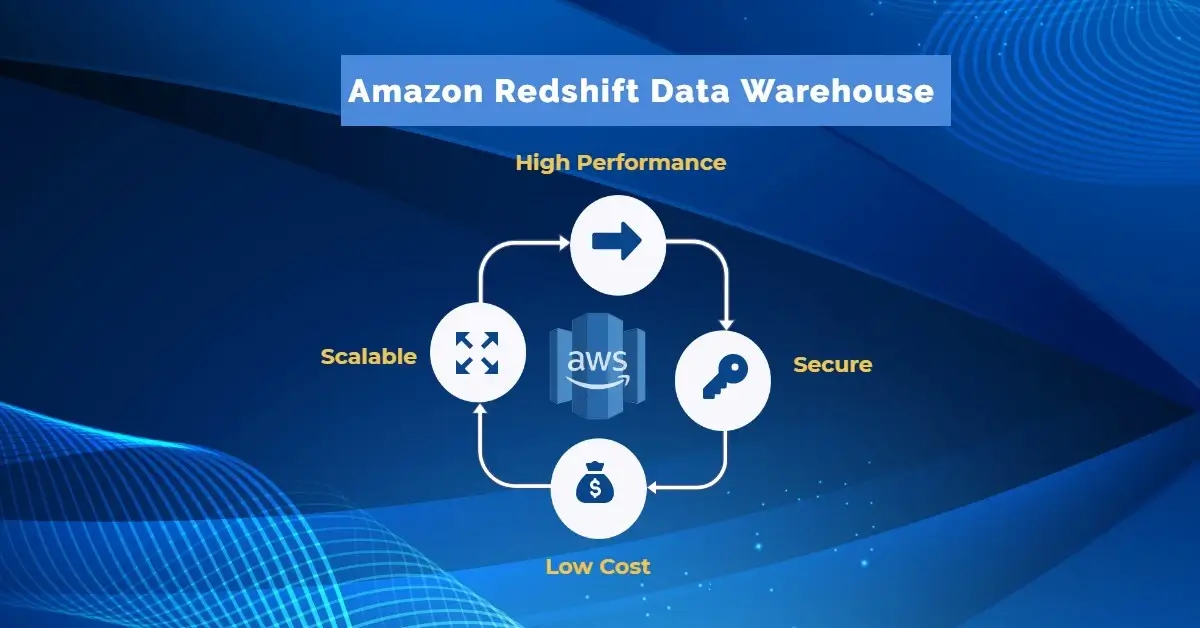
Amazon Redshift is a cloud-based next-generation data warehouse solution that enables real-time analytics for operational databases, data lakes….